Conservation of Expected Jury Probability |
August 22nd, 2014 |
| logic, probability |
- Initial
-
- Selecting "Over 30"
-

- Selecting "Under 30"
-
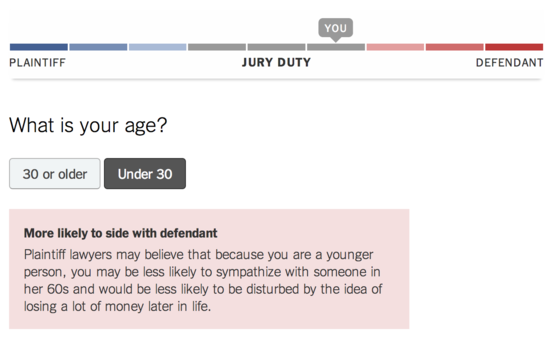
For several other questions, however, the options aren't matched. If your household income is under $50k then it will give you "more likely to side with plaintiff" while if it's over $50k then it will say "no effect on either lawyer". This is not how conservation of expected evidence works: if learning something pushes you in one direction, then learning its opposite has to push you in the other.
Let's try this with some numbers. Say people's leanings are:
| income | probability of siding with plaintiff | probability of siding with defendant |
|---|---|---|
| >$50k | 50% | 50% |
| <$50k | 70% | 30% |
So the lawyers best guess for you is that you're at 60%, and then they ask the question. If you say ">$50k" then they update their estimate for you down to 50%, if you say "<$50k" they update it up to 70%. "No effect on either lawyer" can't be an option here unless the question gives no information.
[1] Almost; the median income in the US in 2012 was
$51k. (pdf)
Comment via: google plus, facebook, lesswrong, substack