Trycontra Implementation |
April 1st, 2019 |
| contra, trycontra |
Since there are only ~300 contra dances and ~40k zip codes I decided to do everything client side. The browser downloads a file of dances (json) that looks like this:
... ["http://www.nbcds.org/", "Santa Rosa CA", "Fridays and Saturdays", 15, 38.44, -122.71, ""], ["http://www.nbcds.org/", "San Rafael CA", "Saturdays", 12, 37.97, -122.53, ""], ["http://www.nbcds.org/", "Sebastopol CA", "Saturdays", 12, 38.4, -122.82, "Larks / Ravens"], ...
And a file of zip codes (json) that looks like this:
... "02451": [42.38, -71.24], "02452": [42.39, -71.22], "02553": [41.71, -70.62], "02559": [41.69, -70.63], "02873": [41.53, -71.78], "02876": [41.99, -71.59], ...
Then in JavaScript in your browser it can map your zip code to a location, figure out which dances are closest, and list the nearby dances.
After I released this, people asked if I could add Canada. I figured that if ~40k US zip codes gave people a 300k download, then ~850k Canadian postal codes would be a lot of data transfer to support just a few users, so I didn't add it.
Recently it came up again, and I realized that since there are only a small number of Canadian dances I could just use the first letter of the postal code, the postal district, to give recommendations:
var postal_districts = {
'A': [47, -56],
'B': [45, -63],
'C': [46, -63],
'E': [46, -66],
'G': [49, -77],
'H': [46, -70],
'J': [46, -74],
'K': [45, -77],
'L': [43, -80],
'M': [43, -80],
'N': [43, -81],
'P': [47, -82],
'R': [50, -98],
'S': [50, -105],
'T': [50, -112],
'V': [50, -123],
'X': [61, -109],
'Y': [61, -139],
}
Update 2019-04-02: my rough locations were not a good fit for Montreal (H), Toronto (M), and a few others, so I've made some of them more precise:
'G': [47.7, -71.6], 'H': [45.5, -73.5], 'K': [45.4, -75.7], 'L': [43.6, -79.7], 'M': [43.6, -79.4], 'N': [42.9, -81.2],
These are super rough, but they're still good enough to answer the question "which of these ~9 dances are nearest to this postal code".
While writing this up I decided to see if I could do something similar with zipcodes. What happens if I just keep the first three digits of each code, located at the average location? (json)
... "008": [18.00, -64.82]" "009": [18.40, -66.08]" "010": [42.26, -72.57]" "011": [42.10, -72.55]" "012": [42.34, -73.23]" ...
Comparing file sizes:
$ for x in zipco*.json; do
echo $x $(cat $x | gzip | wc -c)
done
zipcode.json 308451
zipcomp.json 6785
In other words, this brings us from a 300k download to a 7k one. But how bad an aproximation is it?
A scatter plot mostly shows the few very off ones:
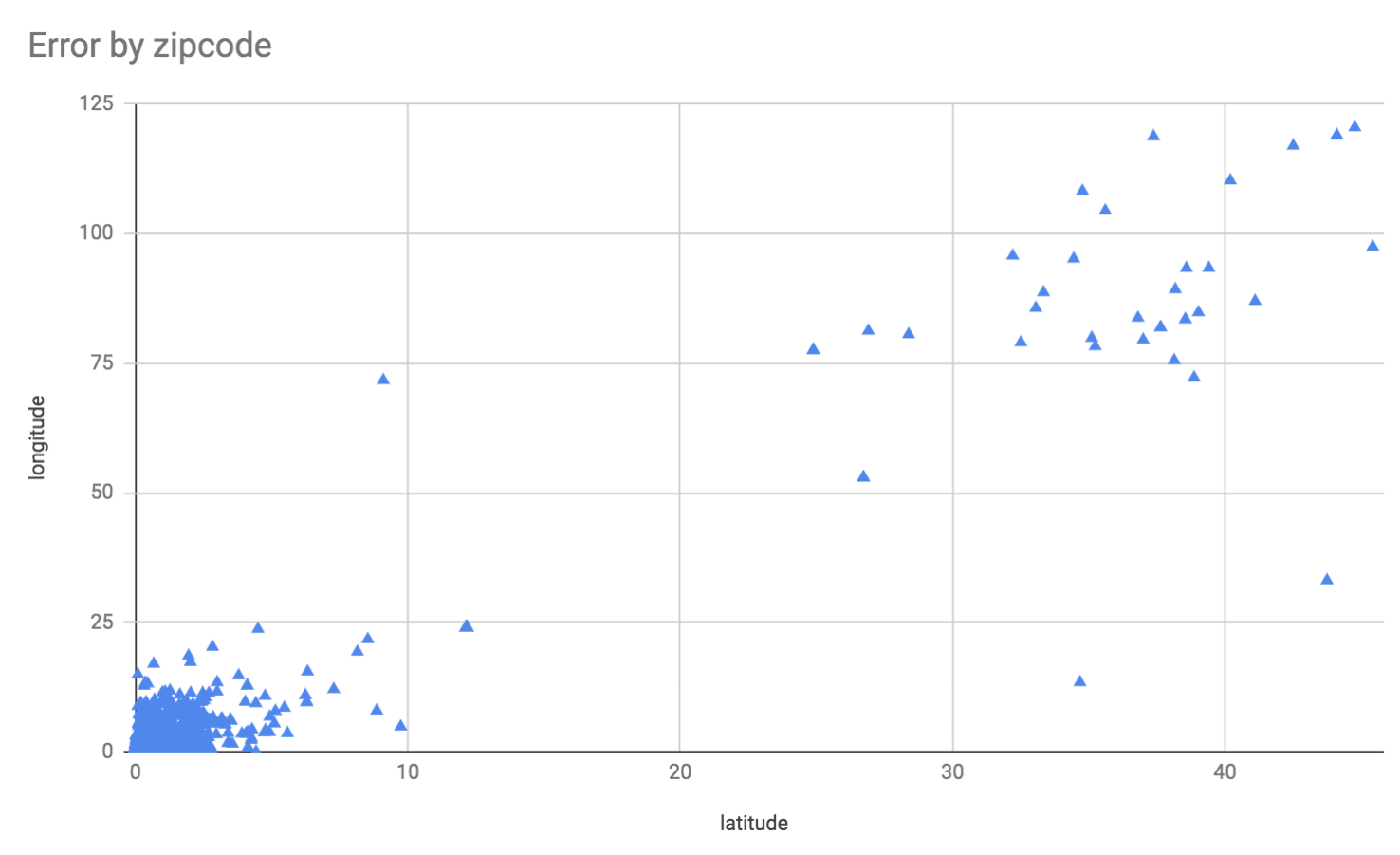
Lets look at a histogram instead:
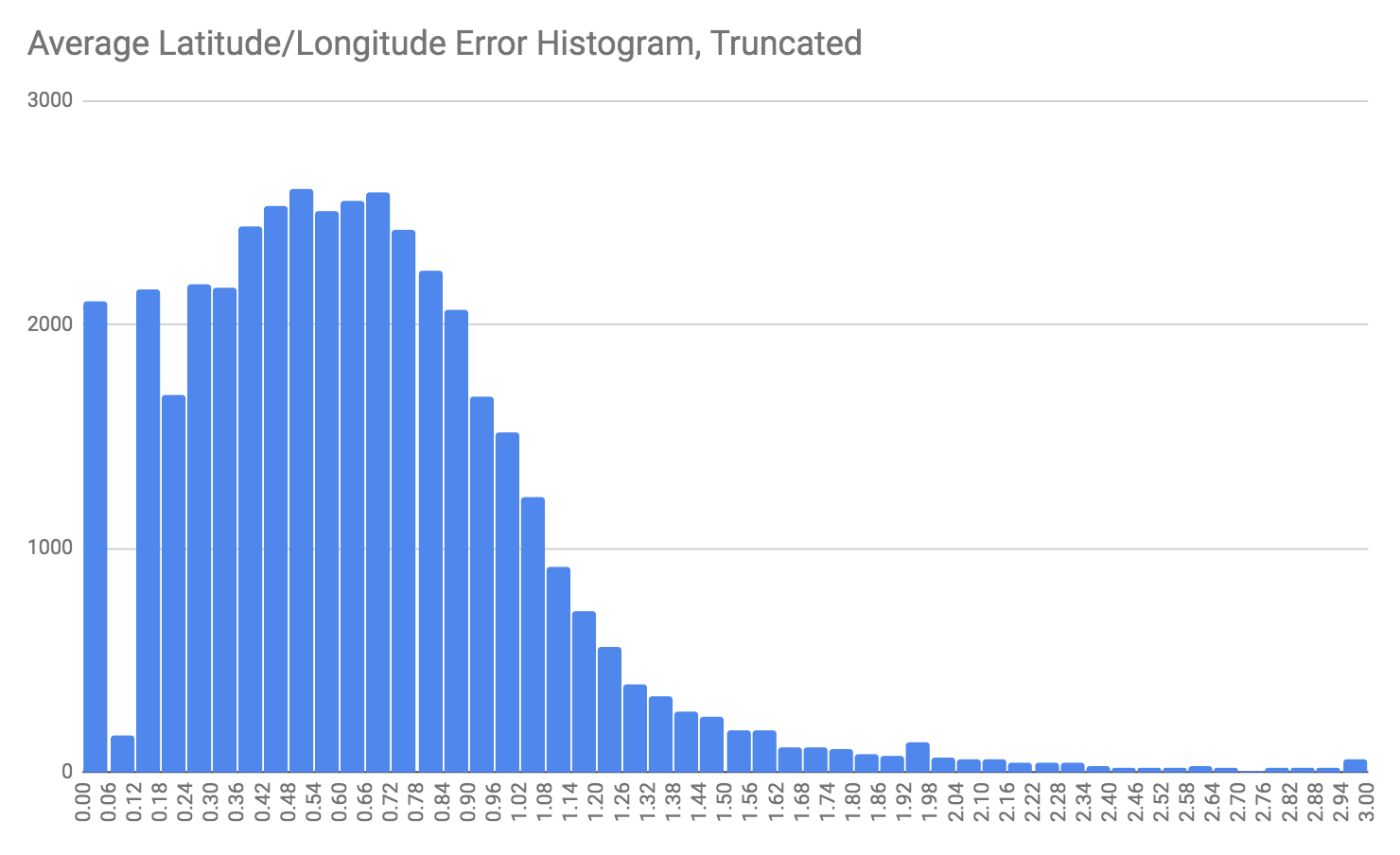
This actually isn't that great. The average error is ~0.8 in lat-lng space, so like 50-55 miles. In some parts of the country that would be fine, but not in really contra-dance-dense regions like the Boston area.
One way to handle this would be to encode zipcode location in an adaptive way, where you use the density of dances to choose how many bits to allocate for the local zipcode mapping. Here's one way to do this:
- For each prefix length (1-4), for each prefix of that length, average all zip code locations matching that preix.
- For each zip code, find the closest dance. Then try shorter prefixes until the closest dance would change.
(It may be easier to understand in code: python. Warning: written quickly and sloppily.)
This makes us a list (json) like:
"068": [41.19, -73.44]" "06804": [41.46, -73.39]" "06812": [41.48, -73.48]"
Of the 47 zip codes starting with 068, 45 are closest to the Stamford CT dance, but two (06804 and 06812) are closest to Cornwall CT.
This approach brings our 300k download down to 60k, which is good though not as good as the 7k we got when we didn't mind if our results changed.
I considered implementing this fully, but since this is a page with a 240k background image I don't think it's worth maintaining the compression.
Comment via: facebook, substack