Benchmarking Bowtie2 Threading |
December 1st, 2023 |
| bio, tech |
I decided to run a few tests on an AWS EC2 with a
c6a.8xlarge 32-core AMD machine. The test consisted of
running one 7.2Gb 48M read-pair sample (SRR23998356)
from Crits-Christoph
et. al 2021 through Bowtie2 2.5.2 with the "Human / CHM13plusY"
database from Langmead's
Index Zone. The files were streamed from AWS S3 and decompressed
in a separate process. See the script
for my exact test harness and configuration.
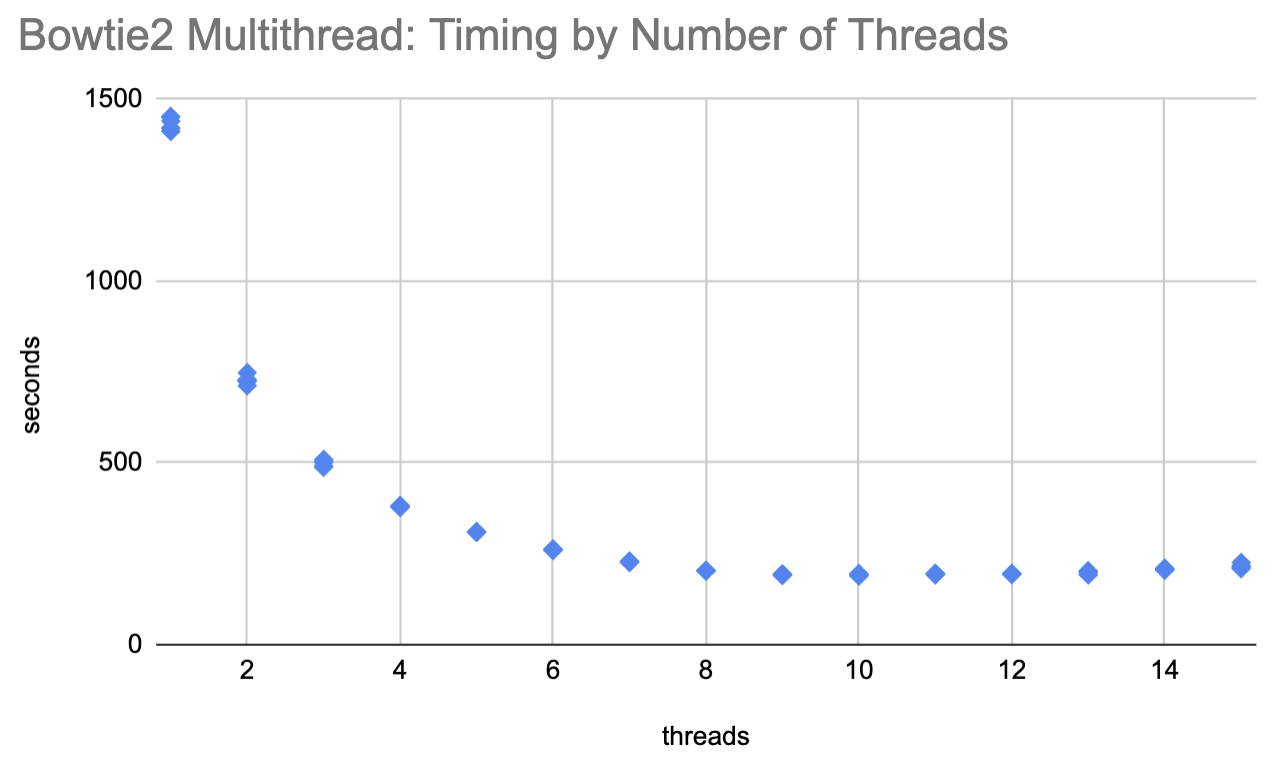
What I found (sheet) was that initially allocating additional threads helps a lot, but after ~8 it was plateauing and after ~10 more threads were very slightly starting to hurt:
Compare what I saw to the best you could hope for, where the task is perfectly parallelizable across threads:
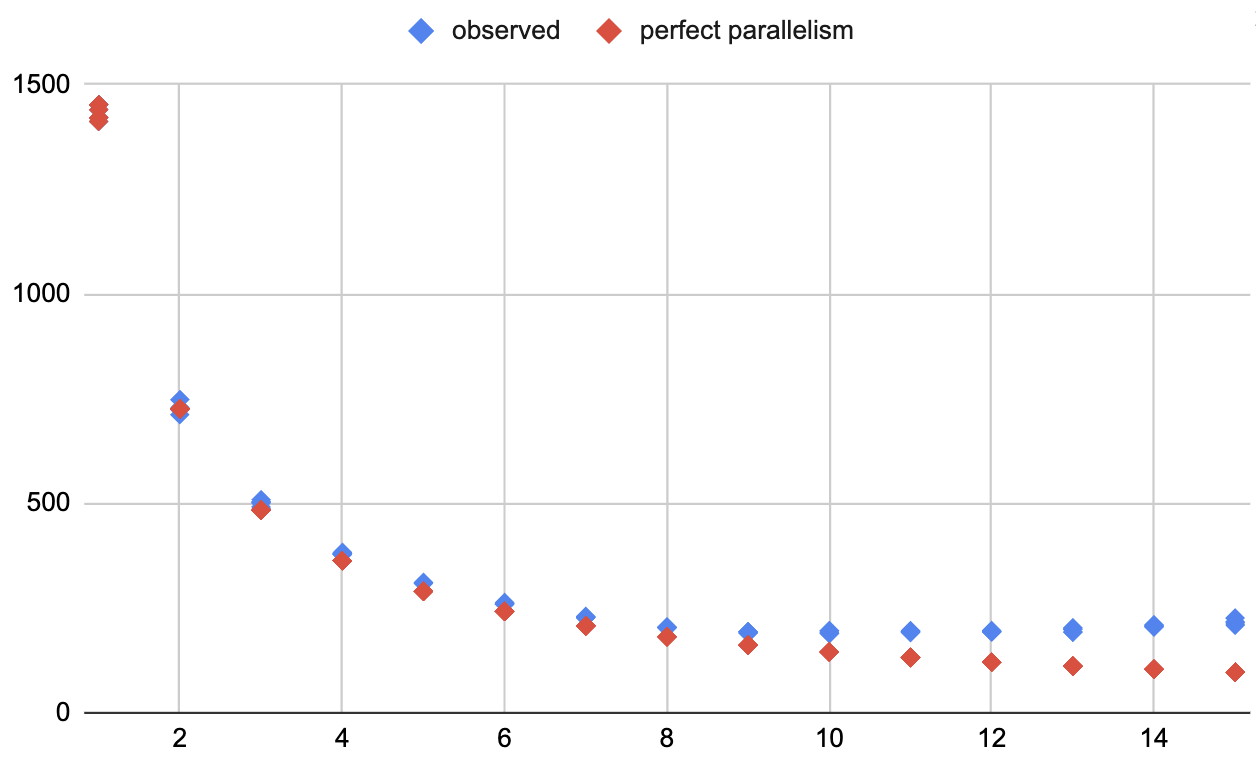
This shows that initially Bowtie2 makes very efficient use of additional threads but, as you'd expect from the plateauing, after ~8 the benefit drops off.
Another way to look at this is to chart how many thread-seconds it takes to process the whole dataset:
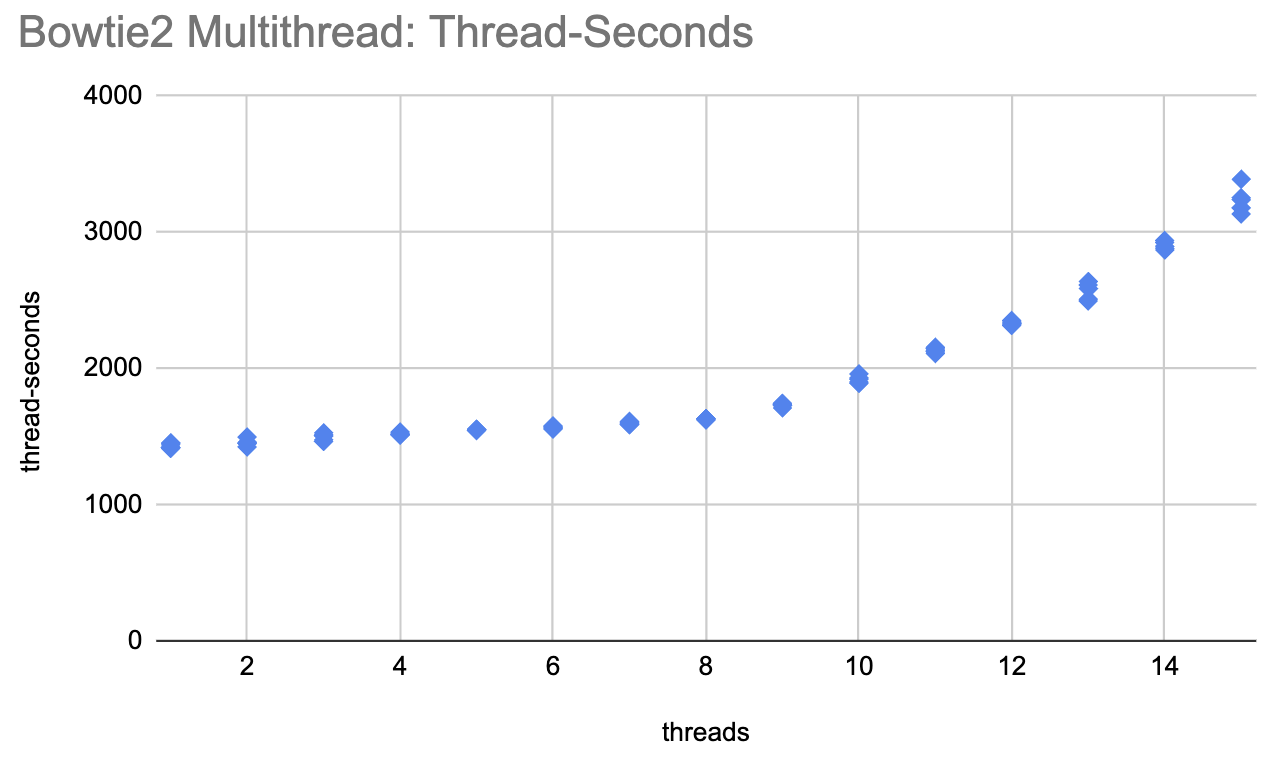
On this plot perfect parallelism would be a horizontal line, and it's pretty close to that up through 8 threads. After that, however, it starts rising much more steeply, showing much less efficient use of threads.
You might wonder how much of this is Bowtie2, and how much is my test
environment. For example, perhaps by the time we get to eight threads
we're at the limit of how quickly this machine can download from S3
and decompress the data? Bowtie2 can't work any faster than the data
arrives! I ran a "null" version of this where I replaced
bowtie2 with paste
(test
script) and found that this consistently took 44-45s. Since it's
all streaming and the fastest run took 189s (4x) I don't think this
was having an appreciable effect.
Overall, it looks like even on a very large machine you shouldn't set
Bowtie2's --threads above 10, and unless you have idle
cores 8 is probably a better value.
Comment via: facebook, lesswrong, mastodon, substack