Sharding the Brigade |
November 13th, 2020 |
| audio, bucket_brigade, singing, tech |
I started, as one always should, with profiling. By far the biggest amount of time was being spent in Opus encoding and decoding. This is what lets us send audio over the internet at decent quality without using an enormous amount of bandwidth, so it's not optional. We're also already doing it in C (libopus with Python bindings) so this isn't a case where we can get large speedups by moving to a lower-level language.
The first question was, if we pulled off encoding and decoding into other processes, could we keep everything else in the same process? The app is built around a shared buffer, that everyone is constantly reading and writing from at various offsets, and it's a lot nicer if that can stay in one process. Additionally, there is a bunch of shared state that represents things like "are we currently in a song and when did it start?" or "who's leading?" that, while potentially separable, would be easier to keep together.
I split the code into a "outer" portion that implemented decoding and encoding, and a "inner" portion that handled everything else. Running a benchmark [1], I got the good news that the inner portion was fast enough to stay all in one process, even with a very large number of clients:
$ python3 unit-stress.py 2.45ms each; est 245 clients 2.44ms each; est 246 clients 2.46ms each; est 243 clients $ python3 unit-stress.py inner 0.05ms each; est 11005 clients 0.05ms each; est 11283 clients 0.05ms each; est 11257 clients
Since encoding and decoding are stateful, I decided that those should run in long-lived processes. Each user can always talk to just one of these processes, and it will always have the appropriate state. This means we don't have to do any locking, or any moving the state between CPUs. I don't know of a great way to manage many sharded processes like this, but since we only need about eight of them we can do it manually:
location /echo/api/01 {
include uwsgi_params;
uwsgi_pass 127.0.0.1:7101;
}
location /echo/api/02 {
include uwsgi_params;
uwsgi_pass 127.0.0.1:7102;
}
...
This also meant creating echo-01.service,
echo-02.service, etc. to listen on 7101,
7102, etc.
Once we have our codec processes running, we need to way for them all to interact with global state. After playing around with a bunch of ideas, I decided on each codec process (client) having a shared memory area which is also open in a singleton global process (server). The client can make blocking RPCs to the server, and because it's so fast that's not a problem that it's blocking.
I decided on a buffer layout of:
1 byte: status (whose turn) 2 bytes: json length N bytes: json 4 bytes: data length N bytes: dataTo make an RPC, the client fills the buffer and, as a final step, updates the status byte to tell the server to take its turn. The server is constantly looping over all of the shared memory buffers, and when it sees one that is ready for processing it decodes it, updates the global state, writes its response, and updates the status byte to tell the client the response is ready.
The protocol is the same in both directions: arbitrary JSON (10kB max), then audio data (200kB max). This means that when we want to pass a new value through shared memory we don't need to update the protocol, but it does mean the server has a bit more processing to do on every request to decode / encode JSON. This is a fine trade-off, since the only part of the system that is too slow is dealing with the audio codec.
I set up a reasonably realistic benchmark, sending HTTP requests directly to uWSGI servers (start_stress_servers.sh) from python (stress.py). I needed to use two other computers to send the requests, since running it on the same machine was enough to hurt the server's performance, and one additional machine was not able to push the server to its limit.
Initially I ran into a problem where we are sending a user summary which, when the number of users get sufficiently high, uses more than our total available space for JSON in the shared-memory protocol. We are sending this for a portion of the UI that really doesn't make sense for a group this large, so I turned it off for the rest of my testing.
With no sharding I measure a maximum of ~216 simulated clients, while with sharding I get ~1090.
Looking at CPU usage, the server process (python3) is at 73%, so still some headroom:
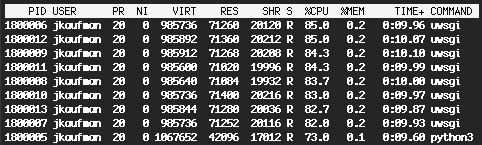
While it would be possible to make various parts more efficient and get even larger speed ups, I think this is will be sufficient for Solstice as long as we run it on a sufficiently parallel machine.
[1] All benchmarks in this post taken on the same 6-processor
12-thread Intel i7-8700 CPU @ 3.20GHz running Linux, courtesy of the
Swarthmore CS
department.
Comment via: facebook, lesswrong, substack