Is Unicode Safe? |
June 14th, 2013 |
| tech, unicode |
Unicode is just too complex to ever be secure.Over the last 25 years Unicode has succeeded. It hasn't displaced all other character encodings, but it's clearly on its way there. It's supported widely enough that it's a compatible choice, new projects use it, and it's becoming the default for more and more systems. Because it can represent nearly every writing system ever used, however, it is extremely complex. This complexity means that most people who interact with it, programmers and otherwise, aren't aware of all it's strange twists. What security issues have come up over the last decade of increasingly widespread use, and do we expect more in the future?
— Bruce Schneier, 2000
In November 2004, Firefox 1.0.1 added support for internationalized
domain names (IDN). This meant that instead of manana.es
a website could be mañana.es. While in Spanish this
is just a nice thing to have, in Japanese, Chinese, and other
languages this was really important. IDNs were built on top of
an older domain name system that only accepted a subset of ascii, so
punycode was
developed to encode it. Internally mañana.es would be
xn--maana-pta.es, but with IDN support people didn't need to
ever see this.
Back in December 2001, Evgeniy Gabrilovich and Alex Gontmakher had published The Homograph Attack (pdf), and described a problem with this system. While in ascii there are very few characters that look like other characters, in Unicode there are many. While Microsoft controlled microsoft.com, Gabrilovich and Gontmakher registered miсrоsoft.com. [1] You probably can't see the difference, and on my system they're pixel-for-pixel identical, but the 'с' and 'о' are actually Cyrillic. At the time very few systems supported IDNs, and few people seem to have paid attention.
In February 2005, however, Eric Johanson registered
pаypal.com (www.xn--pypal-4ve.com). By this
point Firefox, Opera, and Safari all supported IDNs, so this page
could have been be used for phishing. Now people
took the problem seriously, and after a flurry
of
press
browsers dropped
support for IDNs. They've since added support back, with lots
of restrictions to avoid this
vulnerability.
This is given as the standard example
of Unicode security, but several other issues have come up. On
Windows, one way users figure out whether it's safe to open a file is
by checking it's extension. If it's called file.doc it's
probably a harmless document, but if it's called file.exe
then it's a program and might be a problem. But what if you see:
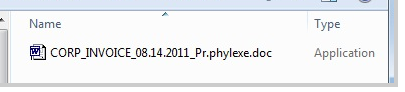
.doc, but it's really ...2011_Pr.phyl[RLO]cod.exe, where [RLO] is Unicode
character U+202E,
RIGHT-TO-LEFT OVERRIDE. In displaying the filename, when Windows sees
the RLO it swaps
the order of the remaning characters, displaying exe.doc.
Tricky.
Another potential Unicode issue is diacritic stacking. A combining character, such as U+0300 or U+0301 means something like "put an accent mark on the previous character". Put enough of them in sequence and they stack up:
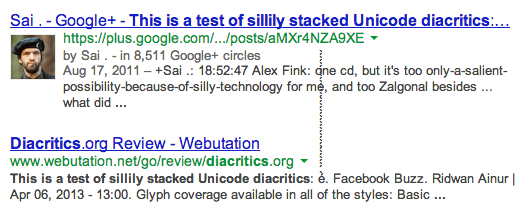
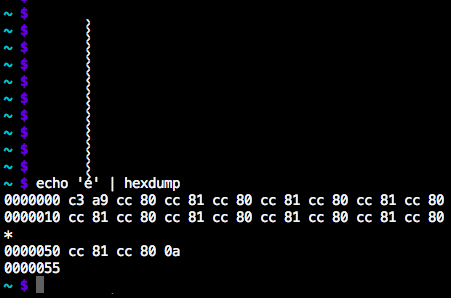
This is a problem because the letter doesn't respect the bounding box that the program designer expected it to fit within. With careful use of combining characters you might be able to use untrusted user input to put an extra dot in just the right place on a target page in order to change its apparent meaning, but all we've seen anyone do so far is just make pages visually confusing.
Imagine someone gives you a url like:
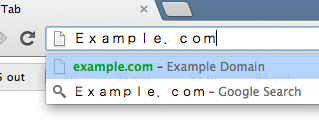
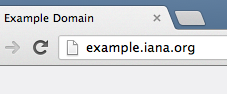
This seems innocuous, but everything that processes urls needs to understand it. Cisco had a problem back in 2007 where their:
devices performing deep packet inspection of HTTP traffic may fail to properly decode URLs encoded using this method, and therefore, fail to recognize potentially harmful URLs.Escaping is another issue. A character might be significant to one program, so before passing data to that program you need to make sure the data doesn't contain those characters. But consider a setup where a program:
- Accepts untrusted user input.
- Escapes it in preparation for putting it in a database.
- Normalizes fullwidth characters to halfwidth.
- Writes to the database.
A good summary of these issues is the Unicode Security Considerations report. It's mostly focused on browser security because that's where most of the issues are today, but most of what's they're applies generally.
Overall, however, this isn't actually that many issues for such a complex system. While there will probably be future exploits where Unicode plays a role, our general acceptance and complacency toward Unicode seems justified.
Update 2013-06-18: Another Unicode security hole: spotify account hijacking. A combination of invalid input and a bug in twisted meant that their username canonicalization wasn't idempotent.
[1] At this time the proposed encoding standard was race, so
they registered bq--at7w373jih7xepx7om7p6zx7oq.com. Now we
use punycode, so today this domain would be encoded as
xn--mirsoft-cjgz.com.
Comment via: google plus, facebook, r/programming, hacker news, substack