Hiring Discrimination |
September 1st, 2015 |
| ism |
Name:
Age:
Race:
Gender:
Verbal Communication Score:
Written Communication Score:
Design Score:
Speed Score:
You want to make sure this is a fair system, so you try giving your
hiring system some fake forms to see how it decides. Unfortunately,
you find that it's it's taking age, race, and gender into account, and
so sometimes says not to hire someone with attribute X when if they
had not-X it would to hire them instead. That's clearly not ok! So
you remove those from the form and try again:
Name:
Verbal Communication Score:
Written Communication Score:
Design Score:
Speed Score:
Unfortunately, you're still seeing a large effect of age/race/gender
on who the system says to hire. You look into it, try some more test
forms, and notice that this effect is stronger for names that signal
age/race/gender. The problem is, even though you've hidden the
explicit signal from your decision makers, they can still see things
that are correlated with it, and might be making a decision based
partly on that. Now, in this case the name had only been on the form
for tracking purposes so you replace it with a number. Problem
solved?
Random Tracking Number:
Verbal Communication Score:
Written Communication Score:
Design Score:
Speed Score:
Sadly no. Even with just these plain scores you're still seeing the system saying you should hire more people from the dominant group. One possiblity is that your scores are just like names: they're strongly correlated with protected attributes for surface reasons. Perhaps your interviewers are from the dominant group and score people as "poor verbal communicators" if they have a different speech style.
Another possiblity is that the qualities that are needed for the job aren't evenly distributed. For example, say people in the dominant group tend to have access to better schooling, which leads to more practice and hence skill at communicating via writing. Written communication is a big part of the job, so you do need to check how people do with it, and you end up with a Written Communication Score that correlates with membership in the dominant group. Now, this is also not ok: as a society we shouldn't be giving better education to some people like this. On the other hand, we probably can't fix this by requiring employers to hire people who won't be able to do the work.
This is the critical question in examining hiring bias: you have some measure that favors people from the dominant group, and you want to figure out how much of this is the measure accurately reflecting individuals' abilities based on their own demonstrated competence and how much of it is prejudice.
In a recent paper, certifying and removing disparate impact, Venkatasubramanian et. al. (2015) describe a way of reducing hiring bias. The system they propose is one where you take the initial form at the top of this post, and then looking at the data tweak some of the values on it, so that no one making a decision based on the forms would be able to substantially discriminate based on age/gender/race/etc.
For example, imagine we're in a world where women get substantially higher SAT scores than men. Instead of comparing people based on their raw SAT score, if we wanted to make sure we weren't considering gender at all we could compare candidates based on their percentile SAT score after breaking down by gender. So a male candidate at the 95th-male percentile would rate equally to a female one at the 95th-female percentile, even though their initial scores were very different. They have a graph of this, where male SAT scores are red, female SAT scores are blue, and the bias-removed SAT scores are black:
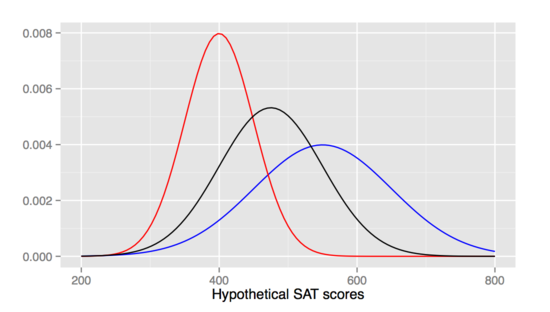
(This is an example of complete repair, but they also talk about doing partial repair, where you use something in between the both-gender percentile and the gender-specific percentile to make a decision.)
The problem with this approach, however, is it doesn't address what we really care about: how prejudiced is the test? In their SAT score example it matters a lot whether men have lower scores for reasons that will lead to them not being good employees, or if they have lower scores for unrelated reasons. If the latter, then basing hiring decisions on "completely repaired" data means hiring equally qualified people who would otherwise be overlooked, while if the former it means hiring substantially underqualified people who were correctly being excluded.
We can't tell these apart with statistics: they both look the same. The only way out is getting better at predicting how well people would do on the job.
(I had originally ended with: "here's a proposal for something simpler than their proposed repairs: run more of the tests from above where you give a set of identical scores to your hiring system attached to fake names that signal age/race/gender. Calculate about how much of a bias there is for each of these attributes, then adjust your hiring thresholds to give people with those attributes a bonus approximately equal to the predicted bias penalty. You don't have to do these at every company: these could be calculated per-industry and published." But as David points out this doesn't really solve the problem unless you have good reason to believe the two sources of bias are similarly sized.)
Comment via: google plus, facebook